One of the most critical tasks in Professional Service Firms is Time Entry, which needs to be accurate and well presented. Spell checking of the narration is an important part of that.
We recently discovered that the dictionary we were using in our time entry system needed to be enhanced with more words than the initial dictionary provided.

Not only did the dictionary lack some common words, but the business wanted to easily able to add new words, for instance a range of technical words, and the names of clients, fee-earners and other important contacts.
The dictionary (https://wiki.openoffice.org/wiki/Australian-English_Spelling_Dictionary) is about the only alternative dictionary easily available, and is covered by the apache licence, so it is easily used. Unfortunately it is not merely a list of words, but a list of words in HunSpell format. For instance the word general appears, but not generals, generalisation and generally. In fact the word general appears as general/q3QSM. The codes after the slash are used to work out the suffixes, but that isn’t built into our software.
To convert the two files to a list of words that can be used, the HunSpell tools need to be downloaded (http://sourceforge.net/projects/hunspell/files/Hunspell/Documentation/), and then compiled. Although I found the instructions didn’t work for Visual Studio, so since I had Cygwin, I downloaded the g++ and other development tools, and compiled unmunch.exe, and then typed
unmunch en-au.dic en-au.aff > en-au-large.dic
which generated over 120K words, more than the 100K words in our current dictionary.
Alternatives to Open Office
If you’d like to spend a bit of money, the Macquarie Dictionary is 3x bigger and at only $7,500 p.a. it could be money well spent.
There’s also a dictionary based on the Open Office dictionary available for sale at http://www.australian-dictionary.com.au/internet-explorer/index.php?ref=KEE3106. The design of this dictionary is to emphasize spellings that are the most accepted, and to excluded less accepted, archaic or esoteric spellings. Let me know if it’s any good. It probably is because no one is improving the Open Office one.
Integrating custom words
I set up an SSIS task to run every morning at 2AM. The objective is to merge the two dictionaries (strictly speaking we may not need to do this, but if the original dictionary is ever expanded it may be useful), and then add in a set of custom words taken from the PMS database including:
- Names of Clients, Fee-Earners and CRM Contacts
- Abbreviations of Fee-Earner names
- Popular user dictionary words
One thing you’ll have to consider if you extract from a user database, is which words do you want to take? Should you take all Client names, or only open ones? All Staff or only Professionals? And how many times does a word have to be in the User Dictionary before you add it to the new dictionary (trust me, the answer is certainly not 1, unless words like arragements and arrangments are words).
You’ll also have to be very careful with case sensitivity. If ABN is a word, is abn? SQL Server is generally set up for case insensitivity, and you may end up with a word that shouldn’t be all CAPS, and some that should. In my first version, I ended up with AND as the only correct spelling of and, and acn as the correct spelling for ACN.
Another thing we considered, but haven’t done, is whether there should be list of words that get excluded from the dictionary because they are vulgar or unprofessional.
If you look at the SSIS Data Flow Task below, you’ll see the 3 respective data sources:
Flat File Source, Flat File Source 1 – the two dictionaries
OLE-DB Source – a stored procedure returning a words from Client, Timekeeper and the customer user dictionary table.
The three data sources are merged together (with the Union All component), Sorted (uniquely), and then outputted to the Flat File Destination. Note that the names have to be output in a Collation order which is case sensitive using the COLLATE SQL operator.

An example of the SQL statement is:
select distinct ltrim(rtrim(word))
from (
SELECT word
FROM UserSpellDictionary
group by word
having count(*)>=5
UNIO
--client
select distinct Firstname COLLATE sql_latin1_general_cp1_cs_as word
from Client
join entity on Client.Entity=entity.EntIndex
join EntityPerson on entitypersonid=entityid
where firstname not like '% %'
and CliStatusType='Open'
...
) a
where word >='A' and word <='ZZ'
and word not like '%.'
and word not like '.%'
and word not like '-%'
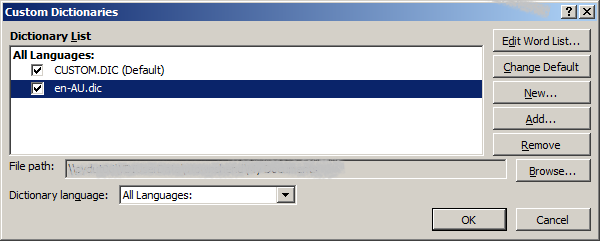
As a bonus a special dictionary is created out of just Client, Fee-Earner and Popular words. This can be added to Word in the Spelling Options Custom Dictionaries using the Add button.